2023. 1. 31. 23:08ㆍReinforcement Learning
Unlike Dynamic programming, from now on we would assume that we don't know the probability dynamics of the environment. (a.k.a. $p_\pi(s',r | s,a)$ ) Model-based and Model-free each is a term for knowing dynamics and not knowing dynmaics of the environment. In real-time assuming that we know the model is not usual. Let's take a look at a case where we play go. Our action to put a go ball in checker board wouldn't determine our next state($s'$) since we don't know the opponent's next move. So int this case we can't use model-based approach.
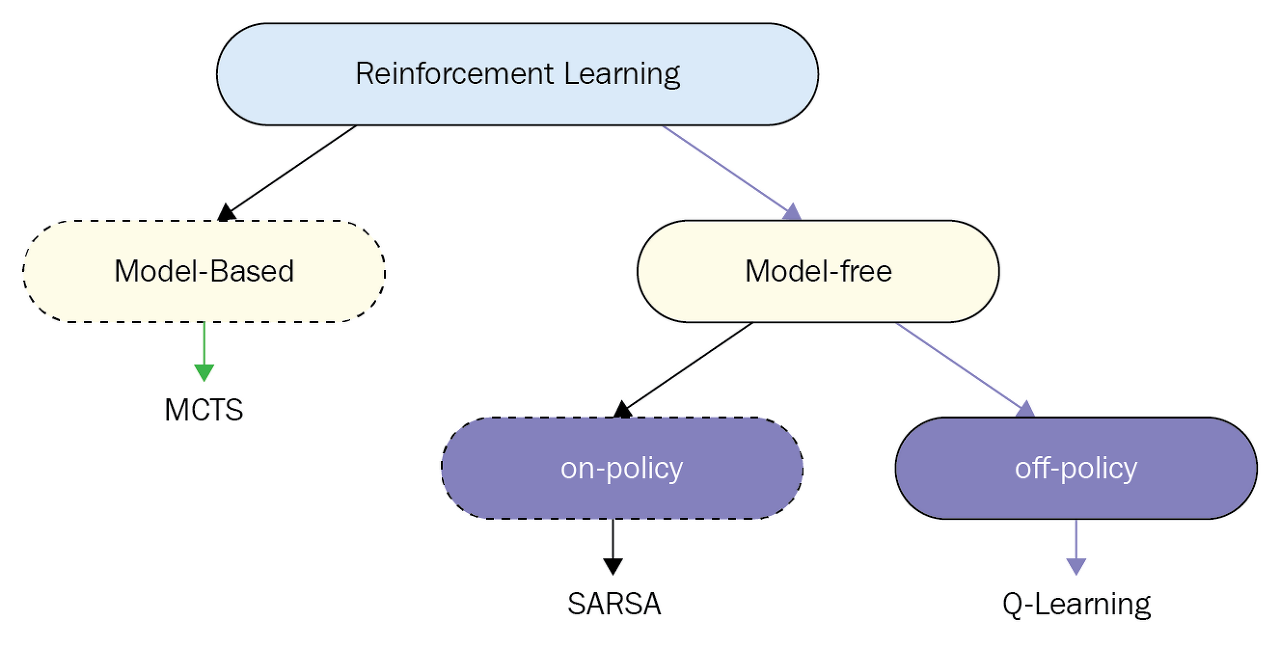
In this post we would look at Monte Carlo(MC) Approach and two Temporal Difference(TD) approach of reinforcement learning. The two TD methods are SARSA and Q-Learning. The main difference between three approach is the target value which is gain (G). The difference is as below.
$$ Monte Carlo Target : G = r + \gamma r' + \gamma^2 r'' + ... $$
$$ SARSA Target : G = r + \gamma Q(s', a') $$
$$ Q-Learning Target : G = r + \gamma max_{a'} Q(s', a') $$
cf) There is also an n-step prediction process which is between TD and MC and this calculates n-step true rewards to predict future rewards meanwhile TD uses 1-step and Monte Carlo uses whole episode.
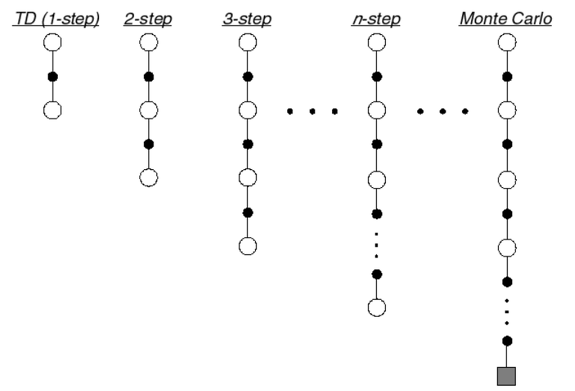
1. Monte Carlo Method
As in the picture we have to unroll total episodic rewards. The drawback of this approach is that we cannot update our values until an episode ends.
2. TD method(SARSA and Q-learning)
1) SARSA (on-policy method)
The reason why we call this on-policy method is because we use the next prediction value($Q(s', a')$) using policy. Meaning that we use policy to find $a'$.
2) Q-learning (off-policy method)
In contrast to SARSA we don't use policy for the newxt prediction value($Q(s', a')$). We just use the maximum of all actions.
Difference between SARSA and Q-learning
SARSA and Q-learning mostly the same except that in SARSA we take actual action and in Q-learning we take the action with highest reward.
Q-learning has the following advantages and disadvantages compared to SARSA:
- Q-learning directly learns the optimal policy, whilst SARSA learns a near-optimal policy whilst exploring. If you want to learn an optimal policy using SARSA, then you will need to decide on a strategy to decay ϵ in ϵ-greedy action choice, which may become a fiddly hyperparameter to tune.
- Q-learning (and off-policy learning in general) has higher per-sample variance than SARSA, and may suffer from problems converging as a result. This turns up as a problem when training neural networks via Q-learning.
- SARSA will approach convergence allowing for possible penalties from exploratory moves, whilst Q-learning will ignore them. That makes SARSA more conservative - if there is risk of a large negative reward close to the optimal path, Q-learning will tend to trigger that reward whilst exploring, whilst SARSA will tend to avoid a dangerous optimal path and only slowly learn to use it when the exploration parameters are reduced. The classic toy problem that demonstrates this effect is called cliff walking.
In practice the last point can make a big difference if mistakes are costly - e.g. you are training a robot not in simulation, but in the real world. You may prefer a more conservative learning algorithm that avoids high risk, if there was real time and money at stake if the robot was damaged.
If your goal is to train an optimal agent in simulation, or in a low-cost and fast-iterating environment, then Q-learning is a good choice, due to the first point (learning optimal policy directly). If your agent learns online, and you care about rewards gained whilst learning, then SARSA may be a better choice.
'Reinforcement Learning' 카테고리의 다른 글
| 4. Dynamic Programming (0) | 2023.01.20 |
|---|---|
| 3. Finite Markov Decision Processes (0) | 2023.01.13 |
| 2. Multi-Armed Bandits (0) | 2023.01.13 |
| 1. RL Introduction (0) | 2023.01.12 |